Xmas Contest 2021 A 問題 展覧会のご案内
本日は Xmas Contest 2021 A 問題の展覧会へご来訪いただき、誠にありがとうございます。本展覧会では、共通のデザインを下地に数々の画伯が仕上げた Xmas Contest 2021 の看板を各々の作品解説とともにご覧いただけます。

解説
この問題は AC のための達成基準が緩めに設けられていることもあり、多様な方法で解くことができます。代表的な解法例と、いくつかのポイントを解説していきます。
マラソン解
ざっくり言うと、「次にきつねたちを動かす点を適当な評価関数で評価し、よさげな点を選んであげる」方法です。
評価関数の例としては、「黒くするべき点を黒くしたら +1 点、白くするべき点を黒くしたら -2 点」というスコアを各きつねに対して計算し、きつね 0 と 1 のうちより悪い方をとる、などが挙げられます。
達成基準を満たすような評価関数の内容には大きな幅があると思いますが、白くするべき点を黒くするペナルティを大きめにする (黒く塗った画素を白に戻すことはできないため)、各きつねに対して計算したスコアのうち悪い方をとる (最悪ケースの損失を抑える) などが基準を満たすために有効です。
また、すべての点に対して評価関数を計算すると結構重くなってしまうので、ランダムに何点かとって評価するなどとして候補を減らすのも有効です。最大で 10,000 回まで線を引けますが、これはかなり余裕をもった回数になっているので、あえて線をもっと少ない回数しか引かないようにした上で評価関数を計算する点の候補数を増やして精度を上げてやるとより上手くいくこともあります。
非マラソン解
線を引くべき箇所をあらかじめ何らかの方法で決めてしまい、そこに確実に線を引いていくといった方法です。
狙った場所に確実に線を引くには、きつねを 2 匹とも同じ画素に置く必要がありますが、これは同じ画素を平均 3 回程度連続して指示すればよく、だいたい 4 回の操作で狙った線分を一本引くことができます。やはり操作回数にはかなり余裕があるので、面倒なことを全く考えないようにするため、常に双方のきつねを同じ画素に置くようにするということも可能です。
線を引く箇所を決める方法としては、手作業でデザインをうまく覆うような長方形をいくつか配置する、横方向に連結な黒い画素に分割するなど、こちらも色々と実現方法があります。
展覧会
本展覧会における展示作品はコンテスト時間中に AC 判定を得た解であり、展示順は AC 時刻の昇順となっています。また、画像は実際の採点時に用いられるものと同じジャッジを用いて生成されました。解法そのものに計算時間や乱数への依存が含まれるなど、同一の画像が再現可能ではない場合があります。
コンテスト終了後に作り上げられた作品については (キリがなくなってしまうので) ここでは取り上げませんが、ぜひ Twitter などで画像やアイデアをシェアしてみてください!
nahco314 画伯

- 黒: 73948 / 86927 (85.07%)
- 白: 114404 / 163073 (70.16%)
- コンテスト開始から一時間で提出された FA 解。解法としては、各文字ごとに黒い画素の連結成分内からランダムな点を選び続ける、というとてもシンプルな手法。このため文字や数字の内部がほぼ全て塗られた状態となっているが、結果として白の精度が 70.16% と基準スレスレを達成しており、ミニマルな美しさがある。
- 「達成基準は自分が適当に書いたマラソン解の精度をだいぶ緩めて適当に設定しただけで、この方法がここまで綺麗に精度 85%, 70% になるとは驚き」とは問題作者の言。
bowwowforeach 画伯

- 黒: 81577 / 86927 (93.85%)
- 白: 129953 / 163073 (79.69%)
- 横方向に連結な黒画素を確実に塗っていくことでカラフルな仕上がりを実現した作品。横に連結な成分ごとに分解する手法は他の画伯も用いているが、その上でもどの順で線を引いていくかで全く異なった味わいが出るのが面白い。bowwowforeach 画伯の場合、ある線を引いたあと、そのまますぐ右へ行くか行かないかが場所によって分かれているのが特徴的。0 と 2 の繋がり方などを見るに、同じ y 座標ですぐ右の線分がある一定の距離より近いかどうかを基準としているのだろうか。文字同士の繋がり方はどこも面白いが、中でも N と T の間は繋がっていたり離れていたりを繰り返しており、閾値の妙が感じられる。
toku4388 画伯

- 黒: 78787 / 86927 (90.64%)
- 白: 120114 / 163073 (73.66%)
- 達成基準の緩さを最大限活用し、大胆にも 2021 の 21 をすべて無視することで、あたかも去年の看板 (あるいは開催 20 回目の看板) であるかのように作られている。まず目を引くのはその点だが、文字から刺々しく飛び出た線によるマラソン解の味も忘れてはいけない。ここでは飛び出た線がいずれも短く収まっている点に特に注目したい。おそらく次の候補点をきつねの現在地から近い点に絞ることで精度を高めているのだろう。これによって文字からたくさんの線が飛び出ていながらも、文字ごとのまとまりがきちんと保たれた作品となっている。
sbite 画伯

- 黒: 78281 / 86927 (90.05%)
- 白: 151527 / 163073 (92.92%)
- 2 匹のきつねに完全に同じ動きをさせている。いくつか見るべき点はあるが、なんといっても特筆すべきはブラシで描き殴ったような力強さを感じさせる上部と、デザインを輪郭を綺麗になぞった下部の対比。元のデザインにおいて上部にかかっていたエフェクトの特徴はどうしても失われがちな傾向があるこの問題で、はっきりとエフェクト有りの上部と無しの下部でタッチが分かれているのは見事。それぞれをもう少し詳しく見ると、上部は X の線が N へ繋がっていたり、A と S の間に何本か線が見えたり、実際は細い線分をたくさん引いているだけにも関わらず太い筆の筆致が見えるような気がする。そう思うと TEST の下が欠けているのも味に見えてくる。下部は全体的な丁寧さの中でも特に、マラソン解などでは潰れがちなうさぎの目が綺麗に見て取れる点は評価が高い。白黒どちらの精度も 90% 超えという高水準でありつつ独自の芸術性も併せ持った作品といえる。
sh_mug 画伯

- 黒: 74700 / 86927 (85.93%)
- 白: 142115 / 163073 (87.15%)
- 長方形でデザインを近似して塗るタイプの解。このタイプの画像では何よりもまず、長方形による領域のカバーの仕方による個性が出る。sh_mug 画伯の場合、非連結ながらも必要十分な働きをしているように見える X や、大胆に斜めの部分をカットした 2 にまず目が行く。それだけでも素晴らしい作品だが、ここではあえて TEST 部分にもさらに注目したい。T, E の上部や E, S の中央・下部など、ひとつの長方形で 2 文字にわたる領域をカバーしていることがわかるだろう。また、長方形の配置だけでなく塗り方についても見ると、基本的には 2 匹のきつねどちらでも塗っているが、一部の線は片方のきつねしか引いていない。これによって画像全体の情報量がただ増えるだけでなく、それぞれの長方形が縦向きか横向きかといった点も表されることになり、結果として画像の深みが増している。
googol_S0 画伯

- 黒: 73950 / 86927 (85.07%)
- 白: 114295 / 163073 (70.09%)
- ひと目見ただけでその異質さが分かる作品。よく見てみると、鉛直か水平な線分だけを用いており、斜めへの移動を全く行っていないだろうことが分かる。長方形でカバーしたり、横に連結な成分に分けたりする方法のメリットとして「ブレゼンハムのアルゴリズムのようなことを考えなくても塗るべき画素が簡単に分かる」という点があるが、この作品はその斜め移動をしないことによるシンプルさというメリットを享受しつつも、先に挙げた方法のような前もっての領域設定を行っていないというのがその異質さの源であろう。きつねは 2 匹とも同じように動かすことを前提として、縦移動と横移動のみを使うとすれば、次の操作の候補数はかなり絞られてくる。そうして最も良い縦横移動を繰り返すとこの画像ができるというのは非常に面白い。
yuusanlondon 画伯

- 黒: 79326 / 86927 (91.26%)
- 白: 120644 / 163073 (73.98%)
- ぱっと見たときの派手さに何よりも目を引かれる作品。マラソン解らしい、非常に長い線分がキャンバス上を乱舞している様が活力を感じさせる。yuusanlondon 画伯は、先に挙げた toku4388 画伯とは逆に、次の候補点を近くに絞ることなく広い範囲から探索したと思われる。それにより、一見乱雑に引かれただけに見える長い線分たちの中からデザインが浮かび上がってくるような、マラソン解の妙とも言える印象を作り上げている。いくつか散見される長い線分のまとまりは、「白い部分もよく通るが黒い部分もとてもよく通る」ので採用されたような線であろう。その中でも、CONTEST の左下から右上に抜ける線分はなかなか人間の目では発見が難しいのではないかと思われる。そうした線を見ることができるのもコンピュータの力を余すところなく活用したマラソン解の楽しみと言える。
komori3 画伯

- 黒: 78339 / 86927 (90.12%)
- 白: 130926 / 163073 (80.29%)
- 一見すると、きつねを同時に動かしつつ大域的なマラソンをやったように見える。だが、komori3 画伯の作品を他のマラソン解、たとえば先の yuusanlondon 画伯の作品と比較してみると、長い線分のまとまりが散見されることは共通しているが、komori3 画伯の方にはそれ以外に文字をはみ出ている箇所がほとんど見られないことに気づく。これは greedy に次の操作点を決めていくような手法とは異なり、きつねの移動経路全体を徐々に最適化していくような手法が用いられた結果と思われる。これにより、greedy なマラソン解のような大胆な線を残しつつも、その他のはみ出しを極力省いて綺麗な作品へと至ることができる。結果として、sbite 画伯の作品に見られた力強い筆のような筆致と、yuusanlondon 画伯の作品に見られた非常に長い線分による活力を高度に同居させた唯一無二の作品へと仕上がっている。
KawattaTaido 画伯

- 黒: 75628 / 86927 (87.00%)
- 白: 155128 / 163073 (95.13%)
- 95% という圧倒的な白の精度と、画像を見ても分かる通り、とても綺麗にデザインがなぞられている。基本的には toku4388 画伯と同じように、いまきつねのいる画素から近い画素だけを次の操作の候補点とするようなマラソン解であろう。toku4388 画伯の作品と同じく 21 が無視されているのは面白い。これはおそらく変形によって 0 と 2 の間が他の文字と比べて広く空いてしまい、短距離の操作のみでは 21 へと遷移することができないためと思われる。さて、大まかな方針は toku4388 画伯と似ているとはいえ、似ているからこそ評価関数や選択基準の違いが画像にはとても分かりやすく現れる。どの文字もほとんどはみ出ることなくきっちりと塗られているため、画像としての印象は toku4388 画伯のものとは大きく異なる。ぴったりとデザインに沿った綺麗さを備えつつも、内部の塗りにマラソンらしい荒々しさが感じられるこの対比が何よりの見所と言えるだろう。
Shun_PI 画伯

- 黒: 79565 / 86927 (91.53%)
- 白: 127072 / 163073 (77.92%)
- マラソン解らしい長い線分がまず目に入るが、これまでのようにまとまった線分がいくつかあるという形ではないところに注目したい。きつねたちがキャンバス上を縦横無尽に動き回って描いたのだろうと想像できる活き活きした線たちが見た目にも楽しい作品である。また、マラソン解と思われる一方で、長すぎる線を引いて線が文字からはみ出るといったことがほとんど起きていない点は驚きに値する。たとえばうさぎの輪郭がとても綺麗にとられていることからも、文字間を渡り歩く線は大胆に引きつつも、無駄な長さは許さないという様子が見て取れる。候補点の選び方や試すパターン数などの設定によって生み出された特徴である。
sugim48 画伯

- 黒: 76270 / 86927 (87.74%)
- 白: 114571 / 163073 (70.26%)
- 横方向ではなく縦方向に連結な黒い成分で分けて描いたと思われる作品。分けたあとの縦線をまとめて引いてしまうのではなく、ある一定の高さごとに分けて細かく描き分けていることが見て取れる。また、文字間を何度も移動しているのか、横に長い線分が背景のように引かれている。これらの要素が複合することで、まるでデザインの文字たちが浮き上がってきたような、他の作品にはない独特の立体感を生み出している。この問題でここまではっきりと立体感を感じさせる画像を作ることができるとは驚きである。
startcpp 画伯

- 黒: 73888 / 86927 (85.00%)
- 白: 115760 / 163073 (70.99%)
- マラソン解らしい荒々しい線たちが目に飛び込んでくるが、その荒々しさをさらに増しているのが 85.00% というギリギリの黒の精度であろう。黒の精度が 85% に達した時点で操作を終了したと思われ、それにより必要最小限の描画となっている。結果として他の画像よりも線と線の隙間の空白がより目立つ形になり、それが線分が飛び交う荒々しさをより際立てて見せている。また、線の密度が低いことにより色使いにも違いが生まれてくることにも注目したい。特に線分の届きづらいキャンバス端 (C や 右上の S や 1 など) では、両方のきつねが訪れたピンクが少なく、青やオレンジのほうが目立つようになっており、遠くから見た際にマーブル模様のように見える。
kemuniku 画伯

- 黒: 74088 / 86927 (85.23%)
- 白: 133559 / 163073 (81.90%)
- 長方形による領域のカバーに見えるが、なんと軸平行な長方形だけではなく平行四辺形や三角形に近い形もあるのは目新しい。これにより特に一段目の XMAS は斜めの線や曲線が多いため、とても綺麗に描き出されていることが分かる。図形の種類が増えて自由度が増えたので文字の形をとりやすくなっているはずだが、一方でうさぎの右耳は綺麗にとっているのに顔がほとんど正方形で塗りつぶされていたりするところに愛嬌を感じる。図形が長方形に限らないためか、内部の塗りつぶし方も確実に塗っていくというよりは、ランダムに近い線の引き方を繰り返していると見えて塗りにも味がある。この塗り方のために図形の端に近い部分はあまり線が引かれていない状態になっており、うさぎの顔や 2 の底辺など、少し真ん中が凹んだような形に見えるのも特徴と言えるだろう。
hari64 画伯

- 黒: 75350 / 86927 (86.68%)
- 白: 160547 / 163073 (98.45%)
- XMAS CONTEST の文字を一見すれば分かるように、細い線で丁寧になぞるように描かれている。この結果、白の精度が 98.45% という驚異の値となっている。きつねの動きを同期させていない状態でこの白精度はまさに圧巻と言えるだろう。文字のエフェクトをほとんど無視して骨組みを綺麗になぞっている点に目が行くが、他にもうさぎの目が非常に綺麗に現れているところに注目したい。全体を通して慎重な線運びを見て取ることができるが、文字間の移動にもそうした特徴が現れているのは面白い。中でも C からうさぎへの移動に明確に出ているが、一本の線で C からうさぎへ移行するのではなく、折れ線を描きながら移行しているのが分かる。この点からも、できるだけ大きな移動を控えて正確に線を引いていこうとする姿勢が感じられる。
sotanishy 画伯

- 黒: 74088 / 86927 (85.23%)
- 白: 128218 / 163073 (78.63%)
- 平行四辺形によるカバーが目を引く一作。平行な 2 つの線分をなぞるように両端点を動かしていきながら内部を塗っていると思われる。その際、端点を動かす速さによる塗りの密度と線の本数のバランスをとった結果だろうか、内部が完全に塗られているのではなく縞模様が出ているのが特徴的である。この塗りが完璧ではないという点がまた別の面白い特徴を生んでいるというところにも注目したい。塗りが完璧ではないということはデザインをはみ出た平行四辺形に対してのペナルティが少なくなるということなので、平行四辺形をデザインに対して大きめにとることができる。同様に軸平行な長方形以外を使っていた kemuniku 画伯と比べるとわかりやすいが、全体的に文字が太めに描かれている。そうした力強い太い線でありながら、塗りが縞模様のようになっていることで圧迫感を薄めており、デザイン性の強い仕上がりとなっている。
Medakaa 画伯

- 黒: 81622 / 86927 (93.90%)
- 白: 140423 / 163073 (86.11%)
- 縦方向の連結成分に分けて塗っている。縦方向への分割は sugim48 画伯に続いての作品になるが、同様の塗り方でありながら見た目は大きく異なっているところが面白い。sugim48 画伯が線分の上下端をブロック的に定めることで立体感を出しているのに対し、Medakaa 画伯は上下端をデザインに忠実にとることで、平面的なマーブル模様といった趣きになっている。特に XMAS CONTEST の部分で文字にかけられたエフェクトを塗りつぶすようにしているが、それでも上下の端は元のデザインに忠実な場所をとっていることから、アウトラインが独特の雰囲気を帯びている。このデコボコとしたアウトラインがマーブル模様的な塗りとマッチしており、他の作品にはないグラフィティ感を演出している。
riantkb 画伯

- 黒: 77735 / 86927 (89.43%)
- 白: 141765 / 163073 (86.93%)
- 塗り方としては横方向への分割だが、分割前になんらかのフィルタの畳込みによる平滑化を行ったように見えるモコモコとしたアウトラインが特徴的。XMAS CONTEST 部分のエフェクトへの対処としてこうした画像処理的なアプローチをとっているのは珍しく、それがこの作品の味にもなっている。先ほど挙げた Medakaa 画伯のものと塗りの方向とエフェクト部分の均し方が異なるが、それによってここまで印象が変わってくるのは面白い。riantkb 画伯の場合はこの滑らかな形と色とりどりの横線が全体的にポップな雰囲気を与えており、かわいらしい出来になっている。またポップさという観点で言えば、本来の平滑化の目的とは外れた 2021 の部分でもフォントの角などが丸められることで全体として統一感が保たれているのは素晴らしい。
abb 画伯

- 黒: 79599 / 86927 (91.57%)
- 白: 135131 / 163073 (82.87%)
- 平行四辺形によるカバーを同期したきつねたちで塗った作品。まず注目したいのは、並べられた図形の外へはみ出た部分がほとんどなく、全体として非常にすっきりと塗られている点。このすっきりした塗られ方に平行四辺形たちの幾何学的な印象が良い具合に組み合わさっている。しかし機械的すぎるといったことはなく、むしろ絶妙に傾いて配置された四角形たちが温かみを感じさせるような出来になっている。この作品の特徴のもう一つが、一部の塗りが不完全で縞模様のようになっている点である。sotanishy 画伯の作品でも似たようなことが起こっていたが、こちらでは縞模様の方向が異なっていることでまた別の効果をもたらしている。sotanishy 画伯の場合は長辺に沿った縞がブラシのような質感を表現していたが、abb 画伯の場合は短辺に沿っていることや端に近い部分で縞模様が現れていることがクールなエフェクト感を醸し出している。
hasi 画伯

- 黒: 77321 / 86927 (88.95%)
- 白: 154461 / 163073 (94.72%)
- 同期したきつねたちによってマラソン的に塗った作品。全体的な印象としては sbite 画伯の作品に近いものを感じるが、比べてみると hasi 画伯の作品はデザインの外にはみ出た長い線分の数が非常に少ないことがわかる。実際、白の精度を高く保つことが比較的難しいはずのマラソン解で hasi 画伯の作品は白精度 94.72% というとても高い水準を達成している。この全体的なはみ出しの少なさが、それぞれの文字から受ける印象にも変化をもたらしている。刺々しいという手触りこそ変わらないものの、こちらは実際の棘というよりはなにか電撃のようなエフェクトを纏っているような雰囲気になっている。「飛び出している」よりかは「纏っている」と感じられるのはひとえに丁寧な塗り方によりはみ出しが極力抑えられているためであろう。
tute7627 画伯

- 黒: 79532 / 86927 (91.49%)
- 白: 135882 / 163073 (83.33%)
- 縦方向の連結成分への分割だが、ひと目見て分かるようにかなり分割が大胆になっている。ある程度短い白成分は無視して上下の黒成分をつなげた結果であろう、O の内部やうさぎの目がまるごと塗り潰されているところに勢いを感じる。これにより長い縦線の本数が多くなるので、全体として縦向きの流れが強調されており、降りしきる雨のような質感が全体に与えられている。このように雨や水の質感を見て取ると、これまた大胆に一部無視されている 2 や 0 の一部などもまるで雨や水を弾く傘のようなものが見える気がして面白い。
eivour 画伯

- 黒: 73891 / 86927 (85.00%)
- 白: 130461 / 163073 (80.00%)
- 黒の精度が 85% ぴったりであることからも分かるように、必要最小限の線だけで仕上げたことが分かる作品。同様の手法を採ったであろう作品として startcpp 画伯のものがあるが、それと比べると eivour 画伯の作品では線分の長さがどれも短いことが分かる。このため eivour 画伯の作品では全体として線の引かれた画素数が少なくなっており、結果として全体の密度がとても低く抑えられている。この密度の低さにより、うさぎや文字の内部に青・オレンジ・ピンク以外に白という色も使われているように見えて賑やかさがより増している。全体として非常に線が少ないながらも短い線分でまとめたことで文字ごとのまとまりはしっかりと描かれており、はみ出し部分と元のデザイン部分の境界線が曖昧になっているのが印象的な作品である。
ksun48 画伯

- 黒: 77102 / 86927 (88.70%)
- 白: 138128 / 163073 (84.70%)
- 縦方向の連結成分への分割をもとに塗った作品。それぞれの縦成分の長さをある一定に抑えてはみ出しを減らし、丁寧に塗っていることが見て取れる。この作品に見られる特徴として、きつねたちが左端の画素を通って降りながら、それぞれの「層」ごとに塗っていったような線が残っている点が挙げられる。この左端の線と、そこから文字へ出ている長い線がとても綺麗に出ているのがポイントで、これによって「層」の存在がよりくっきりと可視化されている。また全体としても左の方から生成されたということが見て分かるようになっており、層の存在とあわせて構造を感じさせる作品となっている。
amitani 画伯

- 黒: 75234 / 86927 (86.55%)
- 白: 118485 / 163073 (72.66%)
- 横方向への分割と塗りだが、とても大胆に長い成分に分割していることが目を引く。N, T, E, S などはほとんど全部ひとつの長方形のように塗り潰されており、白の許容精度 30% ぶんをフルに活用した作品と言える。また、うさぎの顔の輪郭などを見ると分かりやすいが、黒い部分をあらかじめ少し収縮させたような状態から分割を行っていることが見て取れる。これはおそらく XMAS CONTEST 文字部分のエフェクトへの対策であろう。この収縮が画像の左右両端にまた面白い効果をもたらしており、特に C の左や 1 の右が大胆に削られているのは特徴的。また、横方向への分割であるにも関わらず、MA から T、S から T、CO からうさぎなど、縦方向に大きく成分をくっつけているような部分があるのは他の作品にはあまり見られない点である。
KoD 画伯

- 黒: 77015 / 86927 (88.60%)
- 白: 115518 / 163073 (70.84%)
- 縦方向への分割だが、この作品の特徴はむしろデザイン外の部分であろう。少しだけ右に傾きながら上下へ長い線分が次々と引かれており、まるで全体が織物であるかのような質感を与えている。色についても特筆すべき点があり、青とオレンジの線が完全には重ならずギリギリで隣り合っている部分が少し緑っぽく見えることで、普通ではありえない色を描き出すことに成功している。少ない色を交互に点滅させることで実質の色数を増やしていたスーパードンキーコングシリーズを彷彿とさせる工夫で、この問題でもそのようにして描き出されたピンクと緑の織物を見られることには驚嘆せざるを得ない。
semiexp 画伯

- 黒: 86927 / 86927 (100.00%)
- 白: 119195 / 163073 (73.09%)
- 横方向へ分割した上できつねたちを同期させて塗っている作品。その塗りはあまりにも丁寧という他ない。ある程度より短い白い部分を潰しているので、全体としてはデザインをはみ出して塗っている部分こそ多いものの、この塗りの真骨頂は黒精度 100% を達成している点にある。白い部分を 30% だけ塗ってしまっても許されることを活用し、文字へのエフェクト部分まで細大漏らさず拾い上げて塗っていることが見て取れる。はみ出し部分についても、おそらく左から右へ向けて成分を繋げていったことによるものであろう、キャンバスの右端へ向けても黒い成分を伸ばしている点には注目したい。これにより、全体的に左から右への流れが表現されており、特に S, T に見られるような一部だけ右に伸びた箇所が流れに沿った疾走感を演出している。
cubinglover 画伯

- 黒: 82433 / 86927 (94.83%)
- 白: 116057 / 163073 (71.17%)
- 横方向への分割による塗りで、上部と下部で大きく趣きが異なるのが印象的。下部はとても綺麗に塗られており、デザイン間を移動する長い線もそこまで多くない。一方、上部はおそらくエフェクトによる小さい連結成分を丁寧に塗っていったためであろう、デザイン間を移動する線分がとても多くエネルギッシュな仕上がりになっている。その結果、操作回数の都合だろうか、S や ST など、塗り残された部分があるのも特徴的である。特定の文字や場所に塗り残しが出やすいのは一般的にはマラソン解であるが、cubinglover 画伯の作品は横方向への分割ベースでありながら一部の文字にマラソン解に見られるような味が残されているという点が非常に面白い仕上がりとなっている。
Xmas Contest 2020 A 問題の驚くべき結果について
Xmas Contest 2020 の A 問題をご存知でしょうか。さまざまな色のスタンプを押したり引いたりすることで領域の塗り分けを行うという、いかにも派手な見た目の問題です。
さて、今ここに、この Xmas Contest 2020 A 問題の writer を名乗る人物から送られてきた、一通の書簡があります。この書簡には問題の解説のみならず、コンテスト中に提出された数々の画像についての品評が記述されており、たいへん見応えのある書となっています。

コンテストの運営と参加者が共同で創り上げた、この美術展覧会めいた書をいかにすべきか。判断の難しいところではありましたが、今日は節分なので公開することにしました。
解説
この問題の解き方は「手作業」「非マラソン」「マラソン」の三通りに分類されます。
手作業
強く生きてください。
非マラソン
背景が綺麗な長方形をしているので、前景の文字やうさぎを無視すれば正確に塗ることができます。特に、スタンプの一部が画像の範囲外になっていても構わないことを使うと楽だと思います。
背景を塗り終えたら、前景に当たる部分からひたすらスタンプを引いていって黒で塗るのが簡単です。引く基準をどう判断するかはいくらかやり方があると思いますが、場合によっては最後に手作業を併用して調整するなど、案外なんとかなります。
この方法が総合的には最も楽そうで、実際このやり方と思しき提出が多かった気がします。
マラソン
たとえば、「領域ごとに目標の平均色を決め打って、その平均色に近づいたり分散が減ったりするようなスタンプを適当に押していく (スタンプの種類や押す場所はランダムに適当な回数試す)」とかで十分です。
単純ですがわりと実装量は多いことと、やってみるまで AC 基準に到達できるか分からないことで、実際にこういうやり方をした人はほとんどいなかったと思います。
品評会
AC 時刻順です。
takumi152 画伯 (01:41:32)

- 🏆First AC 賞
- スタンプ数: 10704
- お手本のような非マラソン解。背景色は暗くしたほうが前景を引くときにスタンプ数が削減できるが、あえて最もビビッドな赤と緑にしている点は目を引く。多様な取り組み方が考えられ、また作業量も多くなってしまうこの問題で、素晴らしい早さでの提出。
NASU41 画伯 (01:43:45)

- 🏆ミニマリスト賞
- スタンプ数: 1646
- 背景を塗ったあと、前景の引きは手作業だろうか?スタンプ数が非常に少なく、前景の独特のピクセル感がいい味を出している。背景の色分けで > の字形に同じ色を配しているのも特徴的。さらにうさぎの目は後から足されており、結果的にここだけ他にない色となっているなど、見どころが多い。
abb 画伯 (01:59:31)
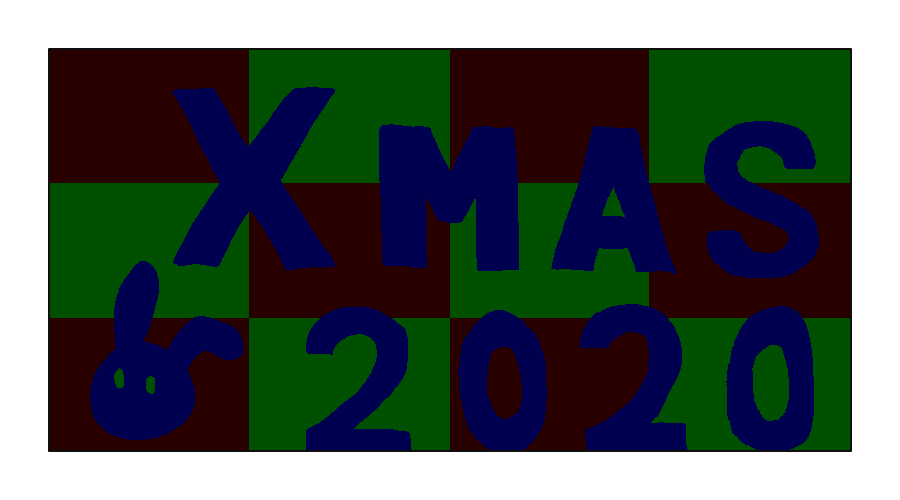
- 🏆ピクセルパーフェクト賞
- スタンプ数: 17943
- おそらく最も驚くべき提出。すべての領域のすべての色成分の分散が 0 となる、完全な塗り分けが行われている。17943 回という多量のスタンプによって実現された完璧な画像は圧巻の一言。
pelno 画伯 (02:17:45)

- スタンプ数: 13449
- 綺麗な非マラソン解だが、うさぎの頭の上の領域や、0 の内側が緑になっている。背景を赤と青基調にし、RGB の中で人間の目に最も明るく映る緑を小さい領域に持ってきたことで、目が痛くなりすぎず、しかしアクセントカラーはしっかりと主張する色使いはお見事。
gojira_ku 画伯 (02:26:11)
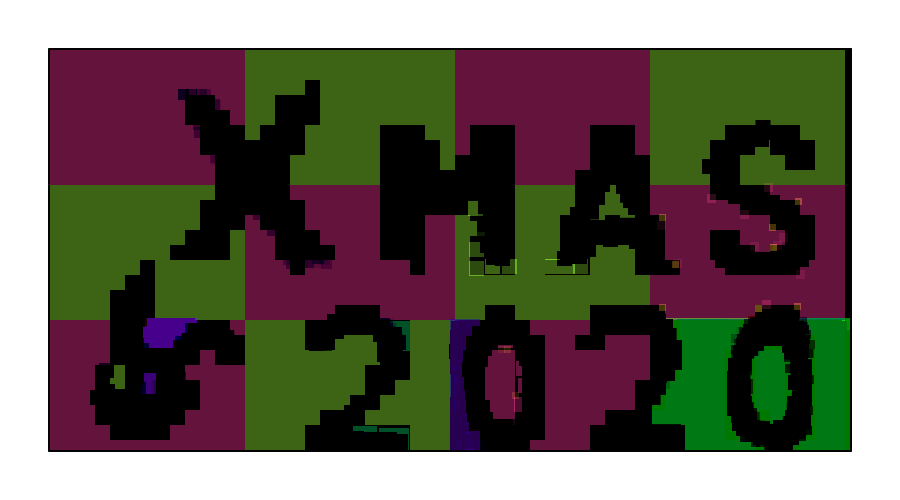
- スタンプ数: 6083
- なんといっても特徴的なのは色。背景を塗るときは最もサイズの大きいスタンプを使うのが楽で、そのサイズのスタンプは R, G, B のうち一成分しか含んでいない。そのため背景はシンプルな赤や緑になりがちなところを、この絶妙に何色とも言い難い色で攻めている。時折混ざる紫系も良く、オッドアイうさぎもかわいらしい。
mtsd 画伯 (02:27:36)

- スタンプ数: 2273
- 非マラソン解だが、これまでと異なる前景の引き方が伺える。正方形スタンプという制約から、必然的にピクセル感・ドット感が出がちなところ、この画像ではじんわりとぼやけた前景が目新しい。S の上部や 0 などに見られるように、文字の境界だけでなく内部にも「かすれ」のような味が出ている点にも注目したい。
Medakaa 画伯 (02:49:32)

- スタンプ数: 3469
- 分散が 700 まで許されることを分かりやすく生かした、背景の縞模様が特徴的。この縞模様は画像の領域外へのスタンプを使わず、かつ最低限のスタンプ数で背景を塗ろうとした結果生まれたと考えられる。M が途中で途切れているように見えたり、2 や 0 の上部が背景の境界で切り取られていたりするなど、背景以外にも「これぐらいなら大丈夫」の結果として生まれた特徴が散見され、他にない独特な画像となっている。
mugen1337 画伯 (03:03:20)
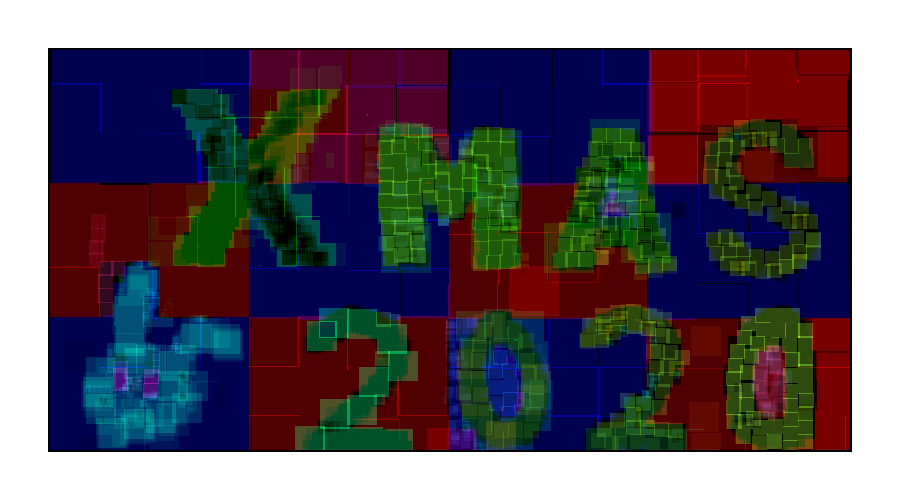
- 🏆ネオサイバー賞
- スタンプ数: 3853
- 背景の塗りを見るに、おそらくすべて手作業だろうか?随所に条件を満たすための努力スタンプの痕が見られ、細かい所まで見て楽しめる。正方形を基調としたパターンながらいわゆるピクセル感ではなく、手作業のブレが生み出す独自の感触。特にうさぎに見られるような、折り重なった正方形によるサイバー感が素晴らしい。また、全体的に明るい色を使っていないにもかかわらず、まるで夜に輝くネオンサインを思わせる刺激的な色に感じられる点も特徴的。とにかく見飽きることがない、非常に芸術性の高い画像といえる。
scol 画伯 (03:18:15)

- スタンプ数: 8996
- これもお手本のような非マラソン解。背景は赤と緑の 3 回押し (成分にして 120) で、無駄のない配色。前景の引き方もとても綺麗で、輪郭が非常にはっきりとしているのが印象的。その輪郭の鋭さも相まって、A や 2 やうさぎなどに見られる、ごく僅かな引き残しがより際立っており、ただのお手本にとどまらないグラフィティ感をささやかに演出している。
Gajumaru 画伯 (03:33:48)
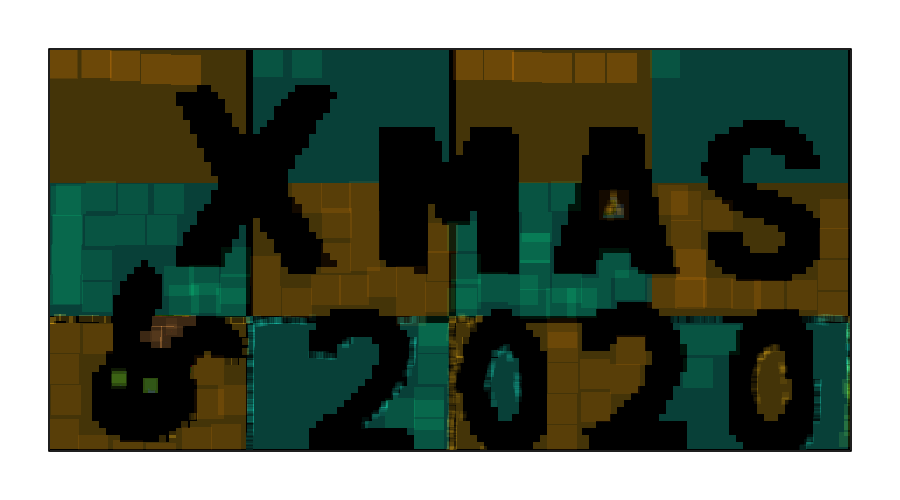
- スタンプ数: 17635
- またも特徴的な色使い。他ではあまり見ない色もさることながら、主に背景のあたりに手作業での調整に苦心したと思しき様子が見て取れるのも面白い。また、うさぎの目が正方形に近いところが、暗闇で目だけが光っているような表現を思わせて印象的。細かい手作業が多そうなので見るべき点も多く、たとえば A の小さな内部領域には非常に細かな調整の跡が見受けられ、じっくり見つめると吸い込まれそうな気持ちになる。
kiwamo 画伯 (03:42:00)
- 🏆グリッチモンスター賞
- スタンプ数: 4992
- かなり少ないスタンプ数で独自性の高い画像を仕上げてきている。白黒背景はこれまでになく、また前景の色も「この領域の色、なんだ?」と思わずじっくり見てしまう引力がある。前景はどれも同じように構成されているように見えて、A だけ異様に細かい文様が透けているところにアクセントが効いている。うさぎの目は正方形の瞳に四白眼のようになっていて、なんだかロボットのキャラクターのよう。全体の印象としては、白黒基調の中に、スタンプのズレによって生み出された赤や青や紫の細いラインが効いていて、グリッチ感がかっこいい。
emthrm 画伯 (03:47:35)

- スタンプ数: 16865
- きっちりと塗り分けられた独特な色の背景と、ピクセル感の中にも境界付近に調整の跡が滲む前景の対照が印象的。前景の輪郭に見られる調整によって、あたかも文字の輪郭の一部が光っているかのように見えて素晴らしい味がある。背景にも境界に黒い線が残っていることから、全体的にくっきりとした印象で統一されている。調整の妙が生み出す味が特徴的な画像でありながら、機械的な印象の方が勝っているという珍しいケース。
tozangezan 画伯 (03:47:36)

- スタンプ数: 8186
- 赤と緑の縦縞を作ったあとに、真ん中だけが光で照らされたような背景の配色が目を引く。M の右下あたりに背景と同じラインで明るい部分が残っている点が、より「縦縞+光」という印象を強めるのに役立っている。スタンプ数は 1 万に満たないながらも、前景の輪郭はかなり綺麗にとられており、また境界のにじみ具合から職人の業といった趣が感じ取れる。
hiikunZ 画伯 (03:49:34)

- スタンプ数: 13894
- 赤と青に差し色の緑という pelno 画伯と同様の色使いだが、緑がうさぎの目にあてられた分かりやすい配色。必然的に構図全体の中でうさぎが目立つ形となっている。背景と前景の塗り引きに目を向けると、ぱっと見たところでは原色の対比ではっきりとした塗り分けに見えて、じっくり見ると塗り残しやにじみ、境界調整のためのスタンプと思しき跡が見えてきて味わい深い。
秋分コンテスト Commentary (JAPLJ side)
解説・コメント (writer: JAPLJ の問題)
D: ゴーストバスターズ
ちょっとだけ問題文が長い以外は、まったく普通の競プロの問題ですね。通常よりごく僅かに長いだけの問題文をよく読んで解けばいいと思います。
問題自体は拡張ダイクストラとか bit DP の練習問題みたいなものなので、特に解説しません。
他の問題でも大量の日本語を書く必要があった (必要は、ないだろ) ため、推敲作業などを全く行っておらず、勢いだけで書かれた一万文字となっています。内容や体裁などに色々と粗があると思いますが、ご容赦下さい。
E: Soup, Abandoned
本来不要な日本語をたくさん書きました。
問題としては、過去に出題した「ウミガメのスープを行って問題内容を当てる」やつのリベンジです。当時は全て手動で質問への対応を行って本当の地獄を見たので、ARTIFICIAL INTELLIGENCE に質問応答を任せることで楽をしようという発想でした。
結果としては、質問対応でコンテスト中に地獄を見るか、インテリジェントな bot を作り上げるためにコンテスト準備中に地獄を見るかの違いでした。
正直、まともな問題内容を bot 相手に特定するのはかなり無理があると分かったので、問題自体は OEIS の特定の数列を出力させるだけのシンプルなものを選びました。それでも融通の利かないスープ相手に内容を訊き出すのは結構大変だと思います。
スープ解説としては、こいつは微妙にステートを持っているので (たとえば問題文について話していると、次の発言が問題文に関するものと解釈されやすくなる、など)、問題文について質問したいときはまず問題文ステートに確実に入るようにしておくと進みやすいです。あとは「数列」「OEIS」「秋分」など特定のキーワードに辿り着ければ問題が見えてくると思います。
H: 手紙 1
本来不要な日本語を書きました。
さて、画像を見ると、知っている人はこれが変体仮名であるとすぐに気づくかもしれません。現代でもたとえば蕎麦屋の暖簾や看板に使われていることがあり、今回の画像にも蕎麦屋で見かける「そ」が入っています。
変体仮名であると分かれば、あとは読むだけです。調べれば一覧が色々と出てくるので、それを使って頑張りましょう。整数列が与えられ、隣り合う二要素が互いに素なのが何箇所あるかを数える問題になります。
I: 手紙 2
本来不要な日本語を書きました。E, H, I は共通の世界観なのかもしれません。秋分を、大事にしよう。
問題文が万葉仮名で書かれています。これも調べて頑張って読んで下さい。文字列が与えられ、それを好きな箇所でふたつに切って最長共通部分列の長さを求めて、すべての箇所についてその和を計算する問題になります。
J: J
J 言語を読み解いて同じプログラムを作る問題……のようでいて、実はほとんど J 言語を読む必要はありません。手元に処理系を入れて動作を見てみれば、何のプログラムか察せる課題が結構あります。
以下、各課題の簡単な説明です。
- Anagram Index ですね。順列をソートしたとき何番目に来るかを答えます。
- 引き算 a-b-c-d-... をやっていきます。ただし J 言語は全ての演算子が右結合なので a-(b-(c-(d-...))) を計算することになります。
- 調べると 32-bit CRC の計算であることが分かります。やりましょう。
- 適当であまり意味のないプログラムです。手元で動作を確かめて再現することを想定しています。プログラムを要素ごとに分解して動かしてみましょう。
- f1, f2, f3 と三種の操作を x に行っているので、それぞれの動作を見てみましょう。f1 は (x[i], i) 要素だけが 1 で他が 0 の行列を作ります。f2, f3 はそれぞれ反射閉包と推移閉包をとります。つまり、三種合わせて、辺 (x[i], i) があるグラフでの到達関係を計算しています。あとは、ある頂点から到達可能な全ての頂点に対応する y の値の総和を求めるだけです。
- 今度は操作が多すぎるし組み合わせ方も複雑なので、とても読めません。手元で動作を確かめることを想定しています。実は f1 から f9 は FFT を使った畳み込みを実装しているので、x と y の和と積による畳み込みを計算して下さい。
- 実行するだけに見えますが、時間がかかりすぎて終わりません。f の正体は特に意味のない複雑な再帰関数です。$: が再帰を意味しているので、再帰関数であることはすぐに分かります。また、引数が整数ひとつのようなのでメモ化すれば早くなりそうです。f の定義の末尾に M. とつけるとメモ化してくれるので、これで十分高速になります。
- Dixon's identity による 3F2 (hypergeometric function) の計算について、条件が満たされているときにその値を求めるプログラムであることが頑張って読むと分かります。なので Dixon's identity に従って計算をして下さい。複素数に対するガンマ関数を計算する必要があり、標準ライブラリでは出来ないと思うので Lanczos approximation とかを使うとよいです。
W: 嗚呼、恍恍惚惚 曠古、杲杲煌煌、兀兀甲骨
この問題に言及する時は「ああこうこうこつこつこうここうこうこうこうこつこつこうこつ」と正しく呼んで下さい。
最近漢字源を買って面白かったので作りました。出題しなかったものにも面白いものが結構あって、いくらでも甲骨クイズができそうですね。
この問題での答えは「呂官不糸眉各上少行阜歩禽癸」です。
X: Legacy A+B Problem
A+B を計算するだけです。が、どうも出力を 7 セグメントで出さないといけないらしいです。さらに Output は "IN A SINGLE LINE"、つまり一行で出力しないといけないらしいです。
一行で 7 セグを表現するなんて、無理では?困ったなあ……。
ところで、2020 年 3 月にリリースされた Unicode 13.0 に Symbols For Legacy Computing というのがあり、ここで 7 セグ表現での 0 から 9 の数字が含まれていますね。というわけでこれで出力して下さい。
Unicode 13.0 の Symbols For Legacy Computing にまともに対応しているフォントは 2020 年の秋分現在ほとんどないので、多分誰も表示はできないと思います。なので親切心からサンプル出力を画像化しておきました。
`: Richard ⅭⅭⅭⅭⅭⅠↃↃↃↃↃⅭⅭⅭⅭⅭⅠↃↃↃↃↃↈↈⅭⅯⅩⅩⅡ
翻訳と日本語業が大変でした。
問題を見てみると、戯曲が書かれており、どうやらシェイクスピアの「リチャード二世」を下敷きにしていることが分かります。
ところで、Shakespeare という、あたかもシェイクスピアの戯曲であるかのようにプログラムが書けるプログラミング言語があります。この「リチャード二千二十万九百二十二世」(を英語にしたもの) が Shakespeare で書かれたプログラムだと思ったときの動作をそのまま提出すれば通ります。
感想 (writer: JAPLJ でないもの、絵しりとりなど)
- A: Introduction to ESP Returns 過去のお誕生日情報をよく復習しているかという問題。これを A に置くの本当に優しくないですね。
- B: Self Introduction KCS が秋分のために改造されて、output checker でユーザ情報がとれるようになって作られた問題。シンプルかつ新しくていいと思います。
- C: ピクトセンス たのしかったです。ワールドカップがお気に入り。
- F: THE EMPTY KCS でも EMPTY シリーズが実施されて嬉しい。通知欄という新要素なのもよい。
- G: くそなぞなぞ 簡単なやつはともかく、難しい方はけっこう大変。
- K: Integer Choice こういうのは 1 問だけ (かつ配点 100) ぐらいがちょうど面白くていいのかな。
- L: Sqrt 秋分癒やし枠。どうしても重くなりがちなコンテストなので、清涼剤は嬉しいね。
- M: I like this 純エスパー枠。こういうのも 1 問ぐらいがちょうどよさそう。出力が三通りなので、エスパーするより提出して入力判別したほうが手っ取り早いと思います。
- N: |n| 秋分癒やし枠。でも思ってたほど瞬殺されまくりではなかったですね。
- O: 沖縄 シンプルに面白い。正規表現を使うといいですよ (条件を満たす文字列を全列挙すると、大変なので)。
- P: Bus Travel tester として普通に解きましたが、面白かった。一旦正の点が取れるところまでいけば、あとはどこが間違っているか調べながら直していけるので、最初に埋めるまでが大変ですね。
- Q: Tozangya ソーシャルディスタンス確保版 こういうのは画像から適切な検索ワードを探る問題になりますね。ラウンドアバウトとかは比較的すぐわかったけど、難易度差もかなり人によりそう。
- R: 私は秋分を知る。 リアルタイム性の高さゆえ、内容について感想を言っている暇がありません。
- S: Cat nuke' Challenge KCS 改造で output checker から提出ソースがとれるようになったので、提出ソース制限系。回避は容易な方ですね。
- T: |あ|み|だ|く|じ| AdBlock パートはともかく、肝心のあみだくじをどうするか……。思考停止手作業書き起こしで 10 分ぐらいでした。
- U: 帰ってきた Picture かなり難しいと思います。元はもっと難しい画像だったとか。
- V: String Achievement 満点は無理があるけど、試行錯誤を繰り返す系で楽しみが長いですね。
- Y: A/B Problem 提出ソース制限系 2。これも回避は容易な方。
- Z: Chess testing 中に挑戦する暇がなかった……。後でやる。
- [: Cheat KCS 改造による最大収穫。本当に面白すぎる。
- : Date Formatter """数"""で表された日付。
- ]: 数列クイズ これもまあまあ癒やし枠。題材は、へ~となりました。
- ^: 🐿 提出ソース制限系 3。これの回避も大変ではないけどちょっと知識が要る。
- _: Echo ゴーストバスターズに並ぶ、秋分中でも極めてまともな問題のひとつ。この問題のためにセット採点情報が出るように KCS が改良されたとか。
- a: Shiritori 2020' 「ンコ文字」を書いてしまい、すみません。いや、直前の絵が「海面」にしか解釈できなかったんだよね、これは真剣に。
- b: 【クエストキーワード提出用問題】Autumnal Equinox Quest お馴染みですね。ほとんどの人はしりとりとスープのものをとっていたようです。それ以外のクエストを引き当てた人はすごい!
Xmas Contest 2019 (JAPLJ side)
おはようございます、JAPLJ です。普段は色々と音楽制作をやっています。(隙あらば宣伝)
Xmas Contest 2019 やりました!
ご参加いただいた皆様、ありがとうございます!コンテストはお楽しみいただけたでしょうか。
今年は昨年と同じ面子 (hos, japlj, snuke) での開催となりました。昨年は軽い構築問をひとつ置いたぐらいだったので、今年はもう少し骨のある (意味深) 問題を作りたいなと思っていましたが、さて実際はどうなったかな……。
コンテスト全体としては、提案された問題が何やら設定や問題文の大部分を共有した複数問に分割できることが多く、気がついたら 12 問という過去最大規模になっていました。誰にも解かれないような問題もなく、かつ幅広く取り組み甲斐のあるセットになったのではと自負しています。
この記事では自分が原案を担当した問題の解説(?)をしていきます。
A: Signboard 1
※「すべて」と言いましたが、インターネットのデータ奔流による混乱や何らかの高次存在の介入などにより収集漏れがあるかもしれません、ご了承ください (連絡を貰えれば追加します)。
少しはちゃんと話をすると、人力 : プログラミング : ツール活用 のバランスをどう取るか?というところが (主に、観戦側の!) 面白味だったと思います。
とはいえ、特にチーム参加で人力を割くコストが相対的に低い場合は、どうしても人力寄りにするのが結局コスパがよくなりそうです。ただ、手作業をする場合でも
- mspaint や GIMP などのペイントツール
- PowePoint や Keynote などのプレゼンテーションソフト (画像単位での移動が楽)
- Finder やエクスプローラーなどのファイルマネージャ (ファイル名の確認が楽)
- 紙とハサミ (プリンタさえ手近にあれば最も楽?)
など多様なツールがありうるので (感想戦が) 面白くなりますね。
writer は、紙片の端どうしのマッチ度を見るだけで局所的に正しい隣接関係はある程度得られることを利用して、プログラムに適宜手動でヒントを与えつつ解きました。
L: Signboard 2
A とつながっている問題なので、先にこちらの解説を……。
紙に書かれた単語のみを使ってスケルトンを完成させる問題です。言ってしまえばそれだけなのですが、ポイントとしては
- 紙片をちゃんと大きな紙に復元してから単語リストを拾う必要がある (一つの単語が複数の紙片に跨っていることがある)
- 紙片を復元するときは A 問題の解答が使えるが、裏面なので左右を反転させて並べる必要がある
- 紙に書かれた単語 (裏面に書かれた単語、ではない) が単語リストになるので、表に描かれている xmas, contest も当然単語リストに入る
あたりです。
不要な単語たちの数はそこまで多くないので、手動でも十分にスケルトンを解くことは可能です。ただ、肝心の単語候補を拾う部分にひねりがあるので、個人的にはスケルトンソルバーはプログラムで書いておいたほうが楽かなと思っています (適当な全探索で十分高速です)。
スケルトンの解答自体は以下のようになります。

Xmas Contest 大好き Xmas Contest フリークの方ならお気づきかもしれませんが、解答に使われている単語はXmas Contest 2011の (Practice を除く) 問題名に使われている単語から取られています (正確には、それに加えて xmas と contest)。
Xmas Contest 好き好き勢であれば、見覚えのある単語たちだな~という印象からいくつかヒントを得られたかもしれません (問題名の単語だけだと枠数に足りないので、xmas/contest を使うことを着想できるなど)。
B: Set of Integers
加算は可換ですが、減算は非可換なので、一見すると |S| > |D| にするのは無茶な要件に見えます。
Xmas Contest だし……思わず、|S| > |D| のケースは存在しない!としたくなるところですが、実は存在します。というのがこの問題でした。
とりあえず先に |S| < |D| と |S| = |D| のケースを片付けておきましょう。
|S| < |D| のケース
まず、N = 1, 2 の場合は |S| < |D| となるような X は存在しません。逆にそうでなければ存在します。
というか、加算が可換で減算が非可換なので、大抵の場合 |S| < |D| となります。
どういう作り方をしてもいいですが、X = {0, 2, 3, 4, ..., n} が分かりやすい例でしょうか。
|S| = |D| のケース
これも案外すぐに見つかります。分かりやすいのは X = {0, 1, 2, ..., n-1} だと思います。
一般に、X の要素が等差数列をなす場合も |S| = |D| になります。
さらに一般に、X が対称なとき (ある a が存在して、x ∈ X なら必ず a-x ∈ X であるとき) も |S| = |D| となります。
|S| > |D| のケース
さて、本番です。先にネタばらしをしておくと、このような条件を満たす集合 X は MSTD set (More Sums Than Differences set) と呼ばれており、探せば多くの論文が出てきます。この名前を知らなくても、たとえば "set of sums and differences" などで Google 検索すると MSTD set に関する文献が多くヒットします。
これらの文献を色々と眺めると、N ≦ 7 では解なし、N ≧ 8 では構成可能 であることがわかります。更に、実際に簡潔な構成法を紹介している文献も出てくるので、それだけで解けます。
コンテスト中に解くだけならそれだけ分かっていれば十分なのですが、ここではもう少し詳しく見ていくことにしましょう……。
といいつつ、N ≦ 7 で解なしであることについては深くは触れません。Hegarty (2007) が次の定理を示しています:
Theorem. 大きさ 7 の MSTD set は存在しない。さらに、大きさ 8 の MSTD set は線形変換によって移りあうものを同一視すれば A_1 = {0, 2, 3, 4, 7, 11, 12, 14} が唯一である。
論文を見てみると分かりますが、証明はずいぶんマッシヴです。細かく追うのは大変なので、ここは先人を信じておくことにしましょう。
コンテスト中には (文献を発見しなかった場合は) 小さい方から探索をぶん回していけばどうも無さそうであることが分かり、あとはもう提出してみるしかないでしょうか。
MSTD set の構成方法も調べると色々と出てきますが、ここでは実際にプログラムで実装しやすくシンプルな Nathanson (2007) による方法を紹介します。
X が対称である場合 (また特に等差数列をなす場合) に |S| = |D| であることを先程見ました。ふつう |S| < |D| となるものを |S| = |D| まで持ってこられるということは、これは非常に惜しいです。対称な集合を少しいじることで |S| > |D| にできないか?ということを考えます。
ところで、最小の MSTD set は N = 8 のときの A_1 = {0, 2, 3, 4, 7, 11, 12, 14} でした。よく見るとこれはとても対称に近いです。具体的には 4 さえ抜けば対称 になっています。
A_1 から 4 を抜いたものを観察すると、 0 2 | 3 7 11 | 12 14 と、差が 2 の部分と 4 の部分に分けることができます。たとえばこれを次のように伸ばすとどうなるでしょうか?
- A* = {0, 2} ∪ {3, 7, 11, ..., 4k-1} ∪ {4k, 4k+2}
A* は対称なので、この状態では |S| = |D| です。ここに A_1 のときと同様 4 を加えると……?
- A = A* ∪ {4}
まず、|S| はどう変わるか考えると、4 + 4 = 8 は A* の要素だけでは作ることができません。なので少なくとも |S| は大きくなる ことが分かります。
では、|D| はどうなるでしょうか? A* の各要素から 4 を引いたものたちを考えてみると
- 0 - 4 = -4 は公差 4 の部分で作れます
- 2 - 4 = -2 は 0 - 2 で作れます
- 3 - 4 = -1 は 2 - 3 で作れます
- それ以降の (4m-1)-4 たちは、そもそも自身が A* に入っているので (4m-1)-4 - 0 で作れます
- 4k - 4 は (4k-1) - 3 で作れます
- (4k+2) - 4 は 4k - 2 で作れます
以上より、|D| は変わりません。すなわち A は MSTD set です。お疲れ様でした。
実際には、他にも様々な構成法があると思います。たとえば、X が MSTD set のとき、十分大きい整数 M を持ってくると
- { a*M + b | a, b ∈ X }
も MSTD set になります。
ある程度小さい MSTD set であればうまく探索したり乱択すると手に入れられるので、それらをこの方法で組み合わせたりいじったりして、より大きい MSTD set を得ることもできます。
さて、B 問題の解説は以上です。が、MSTD set 自体は他にも色々と面白いことが知られています。たとえば Iyer, Lazarev, Miller, Zhang らによるサーベイ論文 を参照してみてください。
一見すると全然存在しないように思える (そして実際コンテスト中にも多くの方が構成に苦労した) MSTD set ですが、実は {0, 1, ..., n-1} の 2n 通りの subset のうち、MSTD である割合が n → ∞ で正である など、意外な結果もあります。
Xmas Contest 2018 ひとこと感想 (ネタバレ有り)
Xmas Contest 2018 ご参加ありがとうございました!
各問題についてひとことずつ重大なネタバレをしていこうと思います (ちゃんとした文章を書くには睡眠時間が足りなさすぎる)。
ちゃんとした文章は……、書くかもしれないし書かないかもしれません。
…(ネタバレ回避用余白)…
…(ネタバレ回避用余白)…
…(ネタバレ回避用余白)…
…(ネタバレ回避用余白)…
- A: いいよねこれ。手作業してもいいし、解答キー生成スクリプト (Javascript) を読むとグラフが埋め込んであるのでそれを使って探索してもいい。
- B: 思ったより解かれなかった感
- C: WA を出さずに書くのは結構たいへん……ですが、けっこう素直に実装すれば一番取りこぼしがなくて WA を出しづらいみたいなところがあって良い。
- D: びっくりするほど解かれなかった……。賢ければちゃんと構成できる (hogloid すげー) んですが、賢くなくても実は多少頑張って探索すれば爆速です。
- E: これはびっくりです。
- F: 唯一の原案。軽めの構成枠がほしいなと思って。
- G: 超締切間際にこういうのが生えてくるのすごいよね。
- H: これも思ったより難しかったっぽい (難易度推定無理すぎる〜)
- I: 想定解はなんかやばかったです。人々が気合の入れた解をたくさん書いて (通して) くれてなんかいい問題っぽくなってて面白い。
- J: 日本語実はそんな大変じゃなくて (実装は多少めんどいけど)、ふつうに計算するパートが意外とむずいよね……。
あんまネタバレせんかったな。
(2n-1)!! (奇数階乗) を mod 2^64 で求める
いろいろ忘れないようにメモ✍しておくとよさそうなので書いておきます。
やること
に対して
以下の奇数をすべて乗算した奇数階乗 (奇数に対する二重階乗)
\begin{align}
(2n-1)!! = 1 \cdot 3 \cdot 5 \cdot \cdots (2n-3)(2n-1)
\end{align}
を で高速に求めます。具体的には
として
時間です。
ここで の部分は多項式の乗算と平行移動 (
の係数から
の係数を求める) にかかります。
やりかた
ソースコードです。Petrozavodsk Camp の問題で出たんですがジャッジがどこか分からない……。いちおう の範囲で愚直なのと比較して verify してあります。
uint64_t oddfact(uint64_t n) { if (n == 0) return 1; static uint64_t comb64[64][64]; if (comb64[0][0] == 0) { for (int i = 0; i < 64; ++i) { comb64[i][0] = comb64[i][i] = 1; for (int j = 1; j < i; ++j) { comb64[i][j] = comb64[i - 1][j] + comb64[i - 1][j - 1]; } } } using poly = array<uint64_t, 65>; poly p = {1}; uint64_t k = 0; for (int b = 63 - __builtin_clzll(n); b >= 0; --b) { if (n & (1ULL << b)) { for (int i = 63; i >= 0; --i) { p[i + 1] += 2 * p[i]; p[i] *= 2 * k + 1; } ++k; } if (b == 0) break; poly q = {}, r = {}; for (int i = 0; i < 64; ++i) { uint64_t pk = 1; for (int j = i; j >= 0; --j) { q[j] += p[i] * comb64[i][j] * pk; pk *= k; } } for (int i = 0; i < 64; ++i) { for (int j = 0; i + j < 64; ++j) { r[i + j] += p[i] * q[j]; } } p = r; k *= 2; } return p[0]; }
やってること
多項式 を以下のように定めます。要は
から始まる
個の奇数の積です。
\begin{align}
P_k(x) = (2x+1)(2x+3)\cdots(2x+2k-1)
\end{align}
すると求めたい は
になるので、これを計算すればよいです。ここで、すべての
の出現に
が掛かっていることから、
で考える場合
以上の高次の係数はすべて
になります。したがって
次から
次までの係数を持っておけば
を評価するには十分です。
この多項式 (の係数) は典型的な繰り返し二乗法の形で効率よく計算できます。
よって上のような多項式の計算を 回やれば目的の
(の係数) が求められ、全体で
時間で
が計算できました。
Xmas Contest 2017 D 問題 Inversion Number 解説
Xmas Contest 2017 D 問題「Inversion Number」の解説です。
問題概要
要素数 N の順列であって、その転倒数を K で割った余りが m であるようなものの個数を 10^9 + 7 で割った余りを求めよ。
制約
- 1 ≦ N ≦ 10^18
- 0 ≦ m < K ≦ 10
解説
まず、N がさほど大きくない場合の解法を紹介します。この場合、
- dp[n][k] := 長さ n の順列で、その転倒数を K で割った余りが k になるものの個数
という DP を行うことができます。長さ n の順列に新たに n+1 を挿入することを考えると、その挿入位置から転倒数の増分がすぐにわかるので、全体として以下のような DP になります。
dp[0][0] = 1; for (int i = 0; i < N; ++i) { for (int j = 0; j < K; ++j) { for (int pos = 0; pos <= i; ++pos) { dp[i + 1][(j + pos) % K] += dp[i][j]; } } }
ここで、ちょうど K 番目の要素を挿入するときの DP 配列に注目しましょう(つまり、N=K となる場合の答えに注目します)。このときだけに注目すると DP 配列は次のように更新されています。
for (int mod = 0; mod < K; ++mod) { for (int pos = 0; pos < K; ++pos) { dp[K][(mod + pos) % K] += dp[K - 1][mod]; } }
これは、dp[K-1][mod] の値が、dp[K] の mod 番目、 (mod+1)%K 番目、(mod+2)%K 番目、……、(mod+K-1)%K 番目に足されているということで、結局 dp[K] の全体に1回ずつ足しているだけです。つまり、
- dp[K][mod] = Σ_p dp[K-1][p]
が成り立ちます。この値は mod に依存していないので、N=K となる場合の答えは m に依存せずすべて同じであることがわかります。すなわち、N=K となる場合の答えは N! / K に他なりません。
さらに、このことに注意しながら N>K の場合を考えましょう。DP の更新式から、dp[n][mod] の値は dp[n-1] から n 個の値を持ってきて足し合わせたものになっていることがわかります。N=K のときに dp[K] の値はすべて同じになることがわかっているので、dp[K+1], dp[K+2], ..., もすべて mod に依らず同じ値を持つことになります。結局、N≧K となる場合の答えは N! / K であることがいえます。
ここまでくれば次のような解法でこの問題を解くことができます。
- N < K のとき、N < K ≦ 10 なので DP や全探索によって解く。
- N ≧ K のとき、N! / K を求める。
残った問題は N ≦ 10^18 のときに N! mod 10^9+7 をどう高速に求めるかという部分です。
N ≧ 10^9+7 のとき N! は 10^9+7 の倍数なので、当然 N! mod 10^9+7 = 0 となります。
N < 10^9+7 のとき、まだ O(N) かけていては間に合いません。そこで、N が何か適当な定数 (たとえば 500万とします) の倍数のときの N! mod 10^9+7 の値をあらかじめ求めてプログラム中にその結果をすべて埋め込んでおきます(これは手元で数秒〜数十秒程度の計算でできるはずです)。すると、任意の N < 10^9+7 に対しての N! の計算が高々 500 万回の掛け算で行えることになります(N 以下の 500 万の倍数で最大のものの階乗の値が埋め込んであるので、あとはそこから N までひとつずつ掛け算していく)。
以上でこの問題を十分高速に解くことができました。